

Writing To A Csv File In Python

![]()
Read, Parse and Write CSV Files with Python.
What are CSV files anyway?🤷♂️
CSV files, the CSV meaning Comma Separated Values, are text files used to store data.
CSV files emulate tabular data, except that each field is separated by a comma.
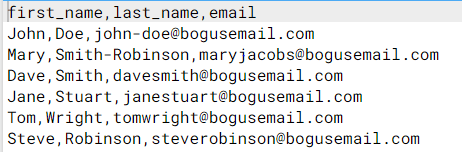
CSV files can be manipulated with Python in either of these ways:
- traditional read/write methods
- the
csvmodule
What would be covered-
In this article, the focus would be manipulating CSV files using Python's csv module, why it is preferred over the usual read/write method would become apparent in a bit.
This article covers the concepts and code (in Python 🐍) used in:
- reading CSV files
- accessing field names/headers
- writing CSV files
- leveraging dictionary readers and writers
Reading CSV files
Without wasting any more time, let's get straight to reading CSV files 🚀.
The CSV file used in this article can be found here
# import csv module import csv # open the csv file with a context manager with open ( 'records.csv' , 'r' ) as csv_file : # using the csv reader function csv_reader = csv . reader ( csv_file ) # loop through the csv_reader iterable object for line in csv_reader : # print each line in the reader object print ( line )
Output:
['first_name', 'last_name', 'email'] ['John', 'Doe', 'john-doe@bogusemail.com'] ['Mary', 'Smith-Robinson', 'maryjacobs@bogusemail.com'] ['Dave', 'Smith', 'davesmith@bogusemail.com'] ['Jane', 'Stuart', 'janestuart@bogusemail.com']
The block of code above prints each line in the CSV file.
This was achieved first by importing the csv module, then a context manager is used to open the CSV file, the CSV file is read into a file object referenced csv_file, using the open() function.
Using the csv module's reader() function, each line in the CSV file is parsed into a reader object, csv_reader.
The reader object is iterable, it returns each line in the CSV file as lists when subjected to iteration.
A quick for loop and a print() function would return each line in the CSV file 😊.
It is important to note, that the reader object iterable when iterated, returns each line of the CSV file in a list object where each comma-separated field is a list item.
This could be helpful to determine what field values would be returned, by indexing the list that is returned for every line.
# open file with a context manager with open ( 'records.csv' , 'r' ) as csv_file : # create reader object csv_reader = csv . reader ( csv_file ) # loop through reader object csv_reader for line in csv_reader : # print the field values under the field header email print ( line [ 2 ])
Output:
email john-doe@bogusemail.com maryjacobs@bogusemail.com davesmith@bogusemail.com janestuart@bogusemail.com
The code block above prints the last field value for every line in the CSV file.
First, the file is read as before, by a context manager, into a file object.
The reader object is created next, it gets iterated through with a for loop, and within the print() function, is where the indexing of each list item (line in CSV file) is done.
Field names
Just as most tables have headers, so do most CSV files also contain field names, the field names of a csv file can be obtained also if present, using the reader object.
# open file with a context manager with open ( 'records.csv' , 'r' ) as csv_file : # create reader object csv_reader = csv . reader ( csv_file ) # iterate through the csv_reader once print ( f 'Field names: { next ( csv_reader ) } ' )
Output:
Field names: ['first_name', 'last_name', 'email']
If the concept of iterators or generators (which are iterators) is not strange, it shouldn't be new to know that when a loop is used to iterate through an iterator, it's the next() function that keeps getting called on the iterator each time.
Here the next() function is called once, which could be seen as looping or iterating through the reader object once, this returns the first line in the CSV file, which would most of the time be the field names.
It shouldn't be confusing that the reader object was called an iterable previously and an iterator here, because all iterators are actually iterable.
If there's any confusion about the difference between an iterator and an iterable, this article from geeksforgeeks should help.
Writing to CSV files
Just as it is possible to read CSV files in Python, it is also possible to write comma-separated values or fields into CSV files.
# open the file to read or get comma separated values or data from with open ( 'records.csv' , 'r' ) as csv_file : # create reader object csv_reader = csv . reader ( csv_file ) # open/create the file to write comma separated values to with open ( 'new_records.csv' , 'w' ) as new_csv_file : # create writer object csv_writer = csv . writer ( new_csv_file , delimiter = '-' ) # iterate through the comma separated values of the initially opened file through the reader object for csv_lines in csv_reader : # write these values to the new file csv_writer . writerow ( csv_lines )
The block of code above would successfully read or copy comma-separated values from a CSV file (records.csv) into another (new_records.csv).
As repeated in previous code blocks, the CSV file is opened within a context manager, two CSV files were opened in the block of code above, the initial CSV file was opened to read comma-separated values out of it, into a csv module's reader object.
The next CSV file is also opened within a context manager, although in this case it was opened so comma-separated values could be written into it.
Next, a writer object was created using the csv module's writer() function, which takes as argument the CSV file object.
The next section in the code block contains a loop that iterates through the reader object, to return each line copied from the first file (records.csv) that was opened into the csv_lines variable, this variable, is passed to the writer object's method writerow(), which writes these values into the last opened file (new_records.csv).
Within the csv.writer() function in the previous code block, a second argument was included - delimiter='-', which would write the values from the previously opened file into the newly opened file, but each field value would be separated by a hyphen (-) instead of a comma (,).

First CSV file (comma-separated values were copied/read from it).

Second CSV file (comma-separated values were written to it).
The second CSV file looks very hard to read and could be problematic if the field values contain the delimiting character (the hyphen, "-"), looking again at the second image, the email field of the second entry (john-doe@bogusemail.com), and the last_name field of the third entry (Smith-Robinson) have hyphens, which is the delimiting character.
CSV files values are not always separated by a comma, as seen in the second file above, the delimiting character could be arbitrary, commas are mostly used as a convention, and in some cases to improve readability.
The csv module's writer() function, knew to place field values that contained the delimiting character in double quotes, as seen in the image above. This would have otherwise made the file hard to read or use in a program.
Using Dictionary readers and writers
Although using the csv module's reader() and writer() functions seems like the standard way to handle CSV files, there's a better way to read from and write to CSV files, that improves code readability, and helps explicitly manipulate and parse comma-separated-values, the way to achieve this would be using the csv module's DictReader() and DictWriter() functions for reading from and writing to CSV files respectively.
Reading CSV files with the DictReader()
The next code block would show how to read from a CSV file using the csv module's DictReader() function
# open the file to be read in a context manager with open ( 'records.csv' , 'r' ) as csv_file : # create a DictReader object using the DictReader function csv_dict_reader = csv . DictReader ( csv_file ) # iterate through DictReader object for line in csv_dict_reader : # print each line in the CSV file as an OrderedDict object print ( line )
Output:
OrderedDict([('first_name', 'John'), ('last_name', 'Doe'), ('email', 'john-doe@bogusemail.com')]) OrderedDict([('first_name', 'Mary'), ('last_name', 'Smith-Robinson'), ('email', 'maryjacobs@bogusemail.com')]) OrderedDict([('first_name', 'Dave'), ('last_name', 'Smith'), ('email', 'davesmith@bogusemail.com')]) OrderedDict([('first_name', 'Jane'), ('last_name', 'Stuart'), ('email', 'janestuart@bogusemail.com')])
Reading from a CSV file using the DictReader() function is very similar to using the reader() function as shown in the code block above.
The first and obvious difference is that the DictReader() function is used in place of the reader() function, thereby returning a DictReader object, as opposed to the reader object of the reader() function.
The second difference would be iterating through the DictReader object an OrderedDict object is returned for each line in the CSV file, as opposed to a list object from a reader object.
Due to the OrderedDict object returned for each line in the CSV file, it makes it easy to index field values, as it would be indexed by the field headers rather than ambiguous index numbers.
A use-case is illustrated in the code block below.
# open CSV file in a context manager with open ( 'records.csv' , 'r' ) as csv_file : # create a DictReader object csv_dict_reader = csv . DictReader ( csv_file ) # iterate through DictReader object for line in csv_dict_reader : # get field values for the email field only print ( line [ 'email' ])
Output:
john-doe@bogusemail.com maryjacobs@bogusemail.com davesmith@bogusemail.com janestuart@bogusemail.com
The above code block prints only the field values under the email header, by indexing with the field header - 'email'. This substantially improves code readability, due to how explicit it is.
Writing to CSV files using the DictWriter()
# open CSV file to read comma separated values from it with open ( 'records.csv' , 'r' ) as csv_file : # create DictReader object using the DictReader function csv_dict_reader = csv . DictReader ( csv_file ) # open new CSV file to write comma separated values into it with open ( 'new_records.csv' , 'w' ) as new_csv_file : # create a list of the field names or headers of the field values that would be written to the file field_names = [ 'first_name' , 'last_name' , 'email' ] # create a DictWriter object using the DictWriter() function. # assign the field_names list above to the fieldnames parameter of the function # pass a tab character as the delimiting character csv_dict_writer = csv . DictWriter ( new_csv_file , fieldnames = field_names , delimiter = ' \t ' ) # write the field header into the CSV file csv_dict_writer . writeheader () # iterate through the values read from the previous file for line in csv_dict_reader : # write the comma separated values to the new CSV file csv_dict_writer . writerow ( line )
Output file:

The code block above would read comma-separated values from one CSV file, and write these values into another CSV file, separating each field value in the new CSV file by a tab character.
Using the DictWriter() function is very similar to using the writer() function, significant differences to be noted would be explained.
Firstly, after opening the second CSV file for writing (within the second context manager), a list referenced by variable name field_names was created, the list items are the field headers or field names of the comma-separated values that would be written into the new CSV file, this explains why it is passed as an argument to the DictWriter() function, by assigning it to the fieldnames= parameter.
Secondly, after calling the DictWriter() function, the next line contains a method of the DictWriter object created in the previous line, the writeheader() method, this just makes sure that the field headers or field names are included when the comma-separated values are written, field headers are written to the top of the CSV file.
Conclusion
Hopefully, the article has been able to put into perspective how easy it is to handle CSV files in Python, thanks to the csv module, and further usage of concepts and methods explained should be a walk in the park.
If the CSV files would be worked with in a data-science-focused setting, using the csv module is not advisable, the pandas library should come in handy in such situations, as it contains functions and objects that are better suited for such tasks.
Although the objects that are very much compatible with pandas functions may be difficult to handle in a traditional Python program.
It should also be clear at this point why the traditional read(), write() methods would not be feasible when handling CSV files.
Hopefully, you've learnt how to-
- read data from CSV files
- write to CSV files
- use dictionary readers to intuitively manipulate CSV files.
Other resources
- Python documentation
- Corey Schafer Series on youtube.
Finally, connect with me on Twitter and LinkedIn, let's vibe ✌🏽.
Writing To A Csv File In Python
Source: https://dev.to/0th/read-parse-and-write-csv-files-with-python-obj
Posted by: hansenmirere.blogspot.com
0 Response to "Writing To A Csv File In Python"
Post a Comment